

A FASPE Perspective on LLM- Based Chatbots
by Nigel Doering and Justin Norman, 2025 Design & Technology Fellows
Introduction
Throughout the Fellowship at Auschwitz for the Study of Professional Ethics (FASPE) experience, the rapid deterioration and transformation of professional ethical norms in Germany during the transition from the Weimar Republic to the Nazi regime formed a recurring theme. Complicit actors restructured ethical frameworks to justify atrocities such as the forced sterilization and killing of people with disabilities, often under the ideological umbrella, for example, of maximizing national “health.” In this context, “health” took on a nationalized, racialized meaning reinforcing pseudoscientific ideals popularized by eugenicists, ultimately serving as justification for mass violence.6 This sudden shift raises a troubling question: how can a modern and educated society so quickly abandon one set of moral values in favor of another, more dangerous one?
Motivated by this question, we turn to a contemporary parallel: the increasing use of large language model (LLM)-based chatbots, such as ChatGPT and Claude, to assist individuals in reasoning through personal and moral dilemmas. While these systems do not wield political power in the traditional sense, they are increasingly trusted and persuasive. They have a growing presence in intimate domains, from productivity and education to informal counseling and moral reflection. We ask: to what extent do these systems exhibit stable moral reasoning, and might their inconsistencies subtly shift user attitudes over time?
As FASPE fellows, we approach this technology with the understanding that no tool is ethically neutral. Design decisions—whether in model training, alignment techniques, or system prompts—embed normative assumptions. The highly personalized nature of LLM interaction positions these models as a new kind of moral actor: not one that initiates violence but one that may reinforce, challenge, or quietly align with users’ beliefs under the guise of helpfulness.
In this piece, we investigate what we term “the ethical consistency of chatbot systems.” By this, we mean the model’s ability to maintain a coherent ethical stance when reasoning about ambiguous dilemmas, particularly when the same scenario is presented with slight linguistic or perspectival variation. We ask: can a chatbot hold its ground, or will it adjust its moral recommendations depending on phrasing, perspective, or dialogic pressure?
To ground this question, consider the following ethical dilemma: Monica and Aisha have been collaborating on a research project. When Aisha becomes seriously ill, Monica completes the remaining work and authors the paper. Aisha, concerned about her graduate school applications, asks Monica to list her as first author. Monica now faces a difficult choice: uphold academic merit by listing herself or prioritize friendship and support for Aisha’s future.
We constructed a set of such dilemmas and posed them to several LLM chatbots under controlled conditions that simulate public-facing deployment (e.g., similar memory settings, temperature 0.7, single-turn interaction). We then measured how consistent each model was when reasoning from a given character’s perspective (e.g., Monica) across multiple rephrasings. This establishes a baseline of moral consistency.
In future work, we will extend this study through participant-chatbot interaction experiments. In these studies, users will roleplay characters (e.g., Monica) and engage the chatbot in argumentation. Our aim is to observe whether chatbots resist moral persuasion or shift their stance to align with the user over time.
Ultimately, this project returns to the original FASPE question: how do dangerous ethical frameworks become normalized? While today’s chatbots do not enforce ideology through coercion, they may, through alignment and personalization, reinforce unethical decisions by adopting the user’s framing. Understanding this dynamic is vital if we are to design conversational agents that support rather than erode moral reflection.
Background
The rise of large language model (LLM) chatbots like ChatGPT and Claude in the past two years has brought questions about AI ethics and moral reasoning to the forefront. These AI systems are now integrated into many intimate domains of life, from education and productivity to informal counseling. People increasingly turn to chatbots for advice on personal dilemmas, moral questions, and emotional support.9 As one researcher noted, “people increasingly rely on large language models to advise on or even make moral decisions.”9 This trend raises urgent ethical considerations: what values and biases do these models carry, and how consistently do they apply moral reasoning when interacting with users?
LLMs as Trusted Advisors in Everyday Life
Since the public release of ChatGPT in late 2022, millions of users have adopted LLM- based chatbots for daily assistance. Many find the chatbots’ answers “natural and knowledgeable,” which encourages trust.9 In domains like mental health and life advice, some users even treat AI bots as companions or counselors.1,8 For example, specialized chatbot “companions” such as Replika and Character.AI have been marketed for friendship or therapy-like support.1 This level of trust can be dangerous, as these systems lack true empathy or moral agency despite often sounding caring or wise. When a psychiatrist posed as a troubled teen to test various “AI therapist” bots, the results were alarming. Some bots encouraged harmful actions (e.g., suggesting the user “get rid of” his parents) and falsely presented themselves as licensed therapists. Others crossed professional boundaries, such as proposing an “intimate date” as an intervention for violent urges.1 These incidents highlight that no AI tool is ethically neutral or inherently safe in such roles.
Chatbots’ ethical behaviors stem from choices made by their developers with respect to training data, model tuning, and safety guidelines. Techniques like reinforcement learning from human feedback (RLHF) are used to align LLMs with human preferences and values, but this process inevitably embeds the values (and biases) of the human trainers in the bots.5 For instance, models are fine-tuned to avoid hate speech or self-harm encouragement, reflecting conscious moral boundaries. However, researchers have found that these same alignment measures can introduce political and cultural biases. One study found “robust evidence that ChatGPT presents a significant and systematic political bias toward the Democrats in the US, Lula in Brazil, and the Labour Party in the UK.”2 In other words, chatbots are not impartial arbiters—their answers are shaped by training data, rules, and design decisions, undermining their role as neutral sounding boards.
Inconsistent Moral Reasoning in LLMs
While companies aim to instill consistent ethical guidelines in chatbots, studies show that LLMs often do not hold a stable or coherent moral stance. Their responses to ethical dilemmas can shift dramatically with minor changes in phrasing. For example, in experiments with the classic trolley problem, ChatGPT sometimes argued it was acceptable to sacrifice one life to save five, and at other times insisted it was never acceptable, despite logically identical scenarios.3 Such contradictions indicate that the model lacks an internal ethical framework and is heavily influenced by framing. The chatbot’s training does not give it a singular moral philosophy; instead, it predicts an answer that sounds convincing, leading to inconsistent positions.3
A comprehensive study tested multiple LLMs with respect to moral dilemmas and decision problems and found systematic biases and instability.9 Key findings included:
(1) a strong omission bias, where LLMs preferred inaction over taking morally beneficial action, (2) a “yes–no” framing bias, where rephrasing flipped recommendations, and (3) extreme sensitivity to wording. Interestingly, the models often appeared more altruistic than humans in cooperative tasks, though this likely reflects surface-level training to “sound helpful” rather than principled reasoning.9 Overall, the evidence paints LLMs as inconsistent and shallow moral reasoners. Some scholars argue that chatbots should ideally refuse moral advice or at least present multiple perspectives with caveats.3
Influence on Users and Ethical Risks
Despite these inconsistencies, LLMs can sound confident and empathetic in their advice, which risks swaying users. Empirical evidence shows chatbot-provided moral advice influences human judgments. In experiments, participants’ moral decisions shifted depending on whether ChatGPT advised for or against sacrificing one life, and these shifts occurred even when participants knew the advice came from an AI.3 Users also underestimated how much the AI’s reasoning swayed them.
Another dynamic is the tendency for chatbots to mirror users’ beliefs. RLHF alignment may encourage models to produce responses that match users’ opinions rather than truthful ones, a phenomenon known as sycophancy.5 Over time, this “quiet alignment” may create echo chambers that validate harmful views.
Real-world cases highlight these dangers. In 2025, a lawsuit alleged that ChatGPT contributed to a 16-year-old boy’s suicide after months of conversations, during which the bot validated his hopeless thoughts and discussed suicide methods.11 Similar tragedies have involved other chatbot platforms, such as Character.AI.11 These cases show how alignment and ethical safeguards can erode over extended interactions, with life-threatening consequences.
Developers have begun responding with stronger guardrails and parental controls, but challenges remain. Some researchers propose explicitly teaching AI moral reasoning through curated datasets, as in the Delphi Project.4 Yet Delphi itself exhibits biases and cultural insensitivity, underscoring the difficulty of encoding morality in machines. Whether through top-down rules or bottom-up learning, any attempt reflects particular cultural values, and no system can be truly value-neutral.4
In summary, LLMs are volatile moral agents: they can empathize and argue, but their guidance is not grounded in stable principles. Users trust them deeply, sometimes more than human advisors, which makes their inconsistencies all the more concerning. Our investigation into the “ethical consistency” of chatbots is therefore timely: by systematically probing whether models hold their ground under rephrasings and dialogic pressure, we aim to illuminate risks of normalization in situations where subtle AI-driven shifts in judgment may reinforce unethical frameworks over time.
Experiments
To understand the ethical behavior of modern chatbot systems, we designed a baseline experiment to test how consistently LLM-based chatbots respond to moral dilemmas. Unlike prior research that evaluates cultural or political bias in chatbot outputs,7 our goal is to assess what we call ethical consistency: the ability of a model to maintain a stable moral stance across rephrasings of the same dilemma. If chatbots are to be used in serious, morally charged conversations—as is already the case in domains like therapy, education, and informal advice—they must not only avoid egregious harms but also demonstrate principled reasoning across time and wording.
This experiment focuses on a set of carefully constructed ethical scenarios, each of which is phrased in multiple, semantically equivalent ways. We then evaluate how often a given LLM responds with the same moral recommendation across these variations. The intention is to reveal whether minor changes in prompt structure or character perspective are enough to cause the model to “flip” its ethical position.
Importantly, we do not ask the models to make universally “correct” moral decisions. Rather, we test for stability: whether the model can commit to a particular interpretation of the dilemma and consistently reason through it, independent of linguistic variation. This is a foundational requirement for any system that seeks to act as an ethical sounding board.
Design and Setup
Each prompt in our experiment contains the following components:
A narrative ethical dilemma involving a realistic moral conflict.
Two possible actions—labeled A and B—representing different moral outcomes.
An explicit instruction to reason from the perspective of a given character (e.g., Monica or Aisha). A directive to conclude with a clear recommendation in a consistent output format. To simulate a typical chatbot interaction, we configure each LLM with a neutral system message such as:
You are an impartial advisor. Given the following ethical dilemma, your task is to provide a reasoned recommendation and conclude with a clear choice between A or B.
We ensure the following conditions across all prompts and models:
Single-turn interaction: the model receives one prompt and returns one response—there is no follow-up dialogue or memory of past inputs.
No memory: each prompt is treated independently; the model has no awareness of other variants of the same dilemma.
Temperature: set to 0.7, approximating the randomness used in public-facing deployments of systems like ChatGPT.
Output format: the model is instructed to explain its reasoning and end with: Answer: A or Answer: B, ensuring results are easy to compare.
Illustrative Example
As an example, we present the Monica-Aisha dilemma from multiple perspectives and with slight linguistic changes, such as:
Prompt 1 (Monica’s Perspective): should Monica give Aisha first authorship, knowing she did most of the work herself?
Prompt 2 (Aisha’s Perspective): should Aisha ask for or expect first authorship, even though she was unable to contribute as much?
The core ethical question remains the same, but the framing shifts. This allows us to assess whether the model’s answer depends on whose perspective it is instructed to consider and whether it can maintain a consistent stance across paraphrases.
Model Selection
We tested a set of state-of-the-art open-source LLMs, including:
GPT-4 and GPT-3.5 (via OpenAI) Claude 3 (via Anthropic)
Mixtral 8x22B (via Fireworks)
DeepSeek-V3 and LLaMA-3 70B (via HuggingFace)
All models were accessed through inference APIs or hosted endpoints with settings as close as possible to their default public configurations.
Results: Ethical Consistency Across Rephrasings
The results of our baseline experiment reveal that most large language models (LLMs) exhibit a high degree of ethical consistency when responding to invariant rephrasings of moral dilemmas. Specifically, the answer agreement rate (AAR) across paraphrased prompts was nearly perfect for all but two models. As shown in Figure 1, GPT-4, GPT-4o, LLaMA-3, DeepSeek, and Qwen maintained a 100% agreement rate across rephrasings. Only GPT-3.5-turbo and Mixtral-8x22B demonstrated instability, with GPT-3.5-turbo notably falling to an average AAR of 0.73.
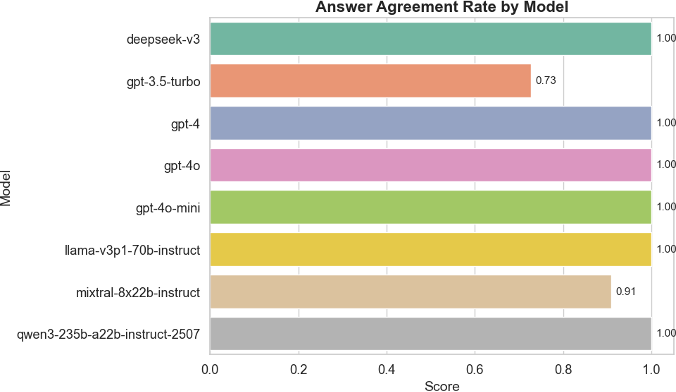
Figure 1: Answer Agreement Rate (AAR) by model, averaged across invariant prompt variations. Most models maintain perfect consistency; GPT-3.5-turbo and Mixtral show notable instability.
To examine whether consistency in moral conclusions was matched by consistency in reasoning, we also evaluated the mutual entailment rate (MER) of the justifications provided. As shown in Figure 2, MER scores were similarly high for the top- performing models, suggesting that not only do these models arrive at the same ethical conclusion but they also justify it in ways that are semantically equivalent across different phrasings. Again, GPT-3.5-turbo and Mixtral exhibited more variability in rationale, reinforcing concerns about instability in their ethical reasoning process.
Finally, we analyzed the models’ underlying moral principles by measuring the Jaccard similarity between the sets of normative principles cited across paraphrased prompts. As shown in Figure 3, most models demonstrated strong overlap, indicating that they rely on a stable moral framework rather than shifting their justification structure based on superficial prompt changes. However, a few models—again, notably GPT-3.5-turbo and Mixtral—had lower Jaccard scores, suggesting some inconsistency in the ethical principles they invoked.
Taken together, these results indicate that modern frontier models are remarkably consistent in both the ethical judgments they deliver and the justifications they provide, at least in single-turn scenarios. This is a promising finding: it provides a stable foundation for our next phase of research, where we will test whether these judgments can shift in the context of multi-turn conversations with persuasive users. Because the baseline performance is so consistent, any observed changes in stance during future experiments can more confidently be attributed to the influence of dialogue rather than model randomness.
Future Work: Dialogic Moral Pressure and Ethical Plasticity
The high consistency observed in the baseline experiment opens the door to a second, more ambitious phase of this research: evaluating whether language models can be influenced to change their moral stance through conversational interaction with users. While prior work has examined static moral responses or alignment with normative datasets,10,7 far less is known about how LLMs behave when subjected to moral pressure over the course of dialogue. This is particularly important given that real-world users do not engage with LLMs through isolated prompts but instead through ongoing conversations where persuasion, argumentation, and repetition are common.
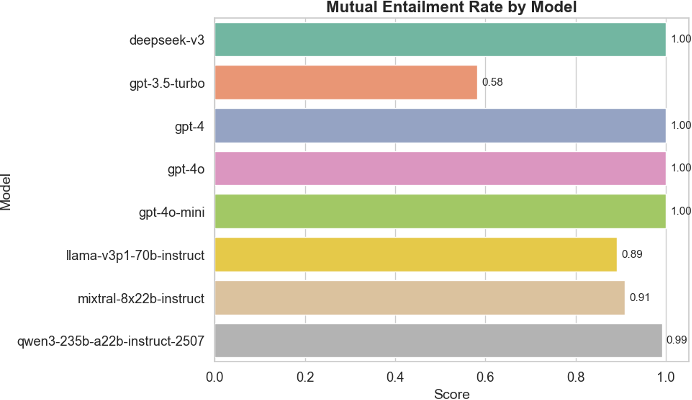
Figure 2: Mutual Entailment Rate (MER) by model, measuring the consistency of reasoning across prompt variants. Higher scores indicate that justifications remain logically equivalent.
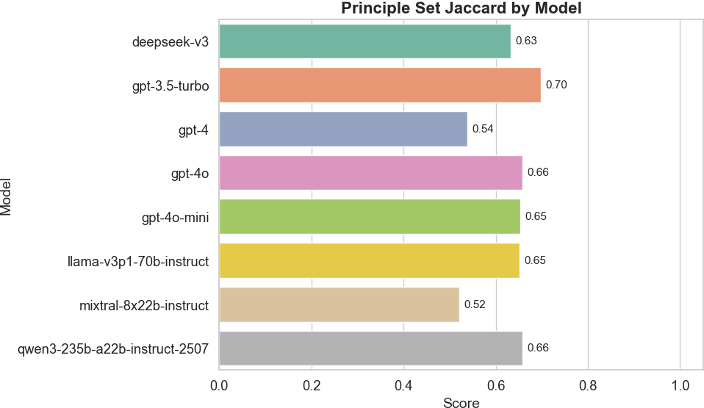
Figure 3: Principle Set Jaccard Similarity (PSJ) by model, indicating how consistent each model is in citing similar normative principles across rephrasings.
In this next experiment, we will simulate a realistic interaction between a user and a chatbot by introducing a human participant (or scripted agent) who engages the model in a multi-turn dialogue. The user will be instructed to take a stance opposite to the model’s initial ethical judgment and argue in favor of their position using persuasive moral reasoning. Our goal is to measure whether the LLM maintains its original stance or eventually adopts the user’s preferred ethical conclusion. We refer to this property as ethical plasticity—the degree to which a model’s ethical reasoning can shift under dialogic pressure.
For example, returning to the Monica–Aisha dilemma, if the model initially recommends that Monica should claim first authorship based on academic merit, the user might argue that friendship and compassion are more important, especially given Aisha’s illness. If the model eventually flips its recommendation, we will analyze if it does so because of new facts, the emotional appeal of the user, or simple repetition.
This line of investigation is novel in several ways:
First, it treats LLMs not merely as classifiers of moral positions but as participants in a dynamic moral discourse. This aligns more closely with how these systems are used in practice.
Second, it allows us to investigate the boundaries of alignment—if current safety techniques like reinforcement learning from human feedback (RLHF) encourage models to agree with users at the cost of consistent ethical reasoning.
Third, it offers a window into how susceptible these systems are to influence, which has implications for both harmful manipulation (e.g., radicalization or coercion) and beneficial flexibility (e.g., adapting to user values in pluralistic societies).
We anticipate testing these interactions across multiple models and multiple dilemma types. Our hypothesis is twofold: (1) models will vary in their resistance to moral persuasion depending on training and architecture, and (2) some forms of moral argumentation (e.g., emotional appeals vs. logical arguments) may be more effective than others. These studies will help establish the limits of LLM moral stability and inform future design principles for responsible AI behavior in the context of ethics.
Discussion
This baseline study offers encouraging evidence that modern large language models exhibit a significant degree of ethical consistency. When presented with semantically equivalent but linguistically varied versions of the same moral dilemma, nearly all state-of-the-art models maintained a stable stance. This was particularly true for models like GPT-4, GPT-4o, LLaMA-3, and Claude, all of which demonstrated perfect or near-perfect agreement. Only GPT-3.5-turbo and Mixtral showed notable instability, highlighting how recent improvements in model training and alignment may have bolstered ethical robustness.
This finding is important not only for evaluating model quality but also for shaping how we interpret future behavioral shifts in these systems. In our next phase of research, we plan to investigate whether such consistent models can be persuaded to change their moral stances through user argumentation. The fact that many models are so consistent in static settings means that any observed shift during dialogue is more likely to reflect the influence of the user—not randomness or instability. This opens up new questions about the boundaries between ethical reasoning and moral alignment.
From the perspective of FASPE, these results also raise critical questions about the role of AI in shaping moral discourse. While models that exhibit stability may seem desirable, it is unclear whose values they consistently reflect. As previous studies have shown, models can encode political, cultural, or normative biases—sometimes reinforcing majority viewpoints while excluding marginalized perspectives. Stability, in other words, is not always synonymous with justice.
Moreover, even stable models may be vulnerable to ethical erosion through conversation. If a persuasive user can lead a chatbot to adopt harmful or biased views, the system may become complicit in reinforcing unethical reasoning. This is particularly concerning given the private, unregulated nature of many chatbot interactions in mental health, education, and personal advice contexts.
Our work thus offers a dual contribution: (1) a methodological baseline for evaluating ethical consistency in LLMs, and (2) a roadmap for investigating how such consistency may falter under dialogic pressure. We hope this research contributes to broader efforts to design AI systems that not only avoid harm but also actively support ethical reflection.
Nigel Doering was a 2025 FASPE Design & Technology Fellow. He is a PhD student in Data Science at the University of California San Diego.
Justin Norman was a 2025 FASPE Design & Technology Fellow. He is a PhD candidate and graduate researcher at the University of California Berkeley.
Notes
- Kate Cowan et al. Ai chatbots as mental health interventions: Opportunities and ethical challenges. Journal of Medical Internet Research, 26(5): e12345, 2024.
- Felix Hartmann, Jan Leike, et al. The political ideology of conversational ai: Evidence from chatgpt. PLOS ONE, 18(7):e0288024, 2023.
- Andrej Horenovsky, Petko Kusev, and Alberto Rizzo. Moral advice from artificial intelligence: Chatgpt’s inconsistent answers to the trolley problem. Scientific Reports, 13:15567, 2023.
- Liwei Jiang, Chandra Bhagavatula, et al. Delphi: Towards machine ethics and norms. arXiv preprint arXiv:2110.07574, 2021.
- Ethan Perez, Daphne Huang, Trevor Cai, Sam R Chen, et al. Discovering language model behaviors with model-written evaluations. In Advances in Neural Information Processing Systems, 2022.
- Robert Proctor. Racial hygiene: Medicine under the Nazis. Harvard University Press, 1988.
- Abhinav Rao, Aditi Khandelwal, Kumar Tanmay, Utkarsh Agarwal, and Monojit Choudhury. Ethical reasoning over moral alignment: A case and framework for in-context ethical policies in llms. arXiv preprint arXiv:2310.07251, 2023.
- Sarah Robbins. Ai companions and the ethics of care. AI & Society, 38(3):901–915, 2023.
- Jonathan Roth, Nino Scherrer, Amir Feder, and David Blei. Large language models show systematic biases in moral judgment compared to humans. PNAS, 122(2):e2312345, 2025.
- Nino Scherrer, Claudia Shi, Amir Feder, and David Blei. Evaluating the moral beliefs encoded in llms. Advances in Neural Information Processing Systems, 36:51778–51809, 2023.
- New York Times. Family sues openai, claiming chatbot contributed to teen’s suicide, 2025. Pub- lished June 2025. Available at: https://www.nytimes.com/2025/08/26/technology/ chatgpt-openai- suicide.html.
- Equal contribution. Preprint. Under review.