

Text Mining of Holocaust-Related Wikipedia Articles
by Ian René Solano-Kamaiko, 2022 Design & Technology Fellow
1 INTRODUCTION
In my case, the FASPE Fellowship Program highlighted the systematic nature of complicity during the Holocaust and the pervasive involvement of professionals at every level.[1, 2, 5, 6] As part of our two-week trip, we were able to meet with Berlin historians studying the Holocaust and were shown artifacts detailing the intimate involvement of companies such as Topf and Sons, which built the crematoria. As I continue to process my fellowship experience, I find myself particularly captivated by these aspects of the Holocaust. Initially, I had only a limited idea of how broadly and deeply involved professionals were during the Third Reich. Even more compellingly, as I learned, many wealthy multinational companies were Nazi collaborators and sympathizers; the majority of which have never been held responsible for their actions.[2–4, 7]
In investigating this reality, I began to wonder how familiar the United States public is with these facts. For example, are everyday Americans aware of IBM’s involvement in the Holocaust?[2–4, 7] Or of the fact that NASA aerospace engineer Wernher von Braun was a member of the Nazi Party and Schutzstaffel (SS)? As a result, I chose to analyze the text from four key Wikipedia articles on the Holocaust. The goal of this work is to understand the content available on Wikipedia. Why Wikipedia though? For starters, they provide a convenient API for working with their webpage content. However, most importantly, Wikipedia articles are some of the top-ranked Google search results when users query for information about a particular subject.[9–12] The information on Wikipedia is generally trusted by the public and may serve as a likely initial resource for a user when seeking to gain preliminary knowledge about a given topic.[8, 10–12]
2 METHODS
This project utilizes a Jupyter Notebook file, which is attached for reference, and heavily makes use of the text mining and sentiment analysis tutorial written by Dr. Jan Kirenz. I first started by installing all the necessary
libraries and dependencies. Afterwards, I initialized a “DataFrame” containing the text from four key Wikipedia articles on the Holocaust: “The Holocaust”, “Nazi Germany”, “Auschwitz Concentration Camp”, and “World War II”. Using the Wikipedia Python Library, which wraps Wikipedia’s API and provides helpful convenience methods, I was easily able to query the content of these articles. After initializing the “DataFrame” with these data, I started performing various transformations such as lower casing and tokenizing the text, omitting all numbers (such as years, e.g., 1945) as well as all words with less than two characters. The tokenization process took these texts and divided them into smaller parts (tokens). This action condenses the information to its relevant components and is useful for finding patterns. In this use-case, I generated a token for every word. Using the Natural Language Toolkit’s (NLTK) corpus of relevant terms, I removed all “stop words,” that is, words with limited research value (e.g., “will”, “and”, “or”, and “has”), from the text tokens.
After performing this data processing and preparation, I determined the frequency distributions of the tokenized words and removed any words with a frequency less than or equal to four. Additionally, I performed a word lemmatization process that groups together the inflected forms of a word so they can be analyzed as a single item (e.g., a word like “better” might have the lemma “good”)
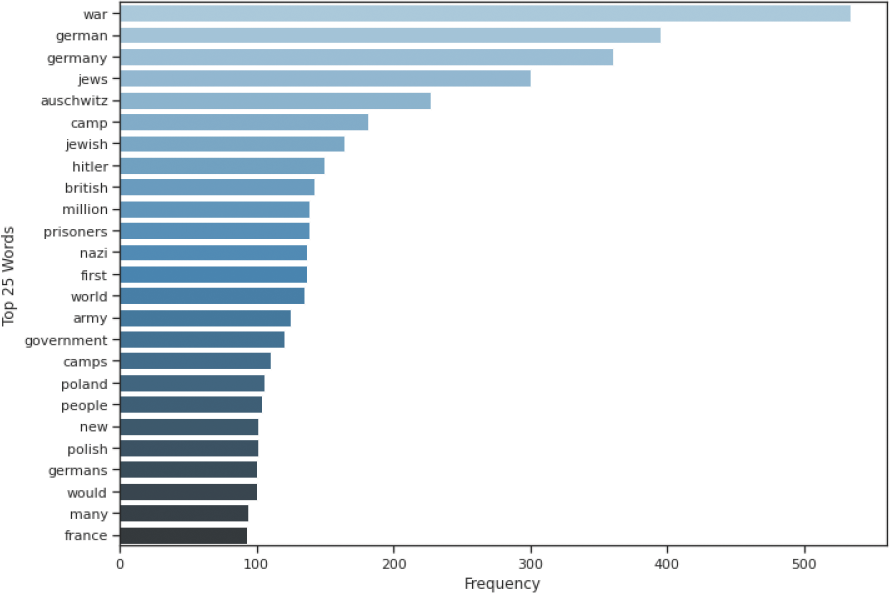
Subsequently, I rendered a word cloud of the data. The size of the text in the word cloud corresponds to the term’s frequency (Figure 1). In addition to visualizing the corpus as a word cloud, I also created a bar chart containing the most common 25 words (Figure 2). In the chart, the word “war” unsurprisingly appears the most times, 534 times, and the word “France” rounds out the top-25, appearing 93 times throughout the text.

After creating these general data visualizations displayed above, I wanted to investigate these corpora further regarding their language. Specifically, I wanted to explore whether the text adequately documents the systemic nature of the Holocaust. I created a list containing 50 words based on 3 key search terms: “systematic”, “pervasive”, and “complicity”. Using Oxford Languages online dictionary, I found 47 additional words that are synonyms for the 3 key search terms.
Using this compiled list (Figure 3), I searched for the frequency distributions of these words in the text. After finding the corresponding word frequencies, I sorted the data in descending order and rendered the words in a table.

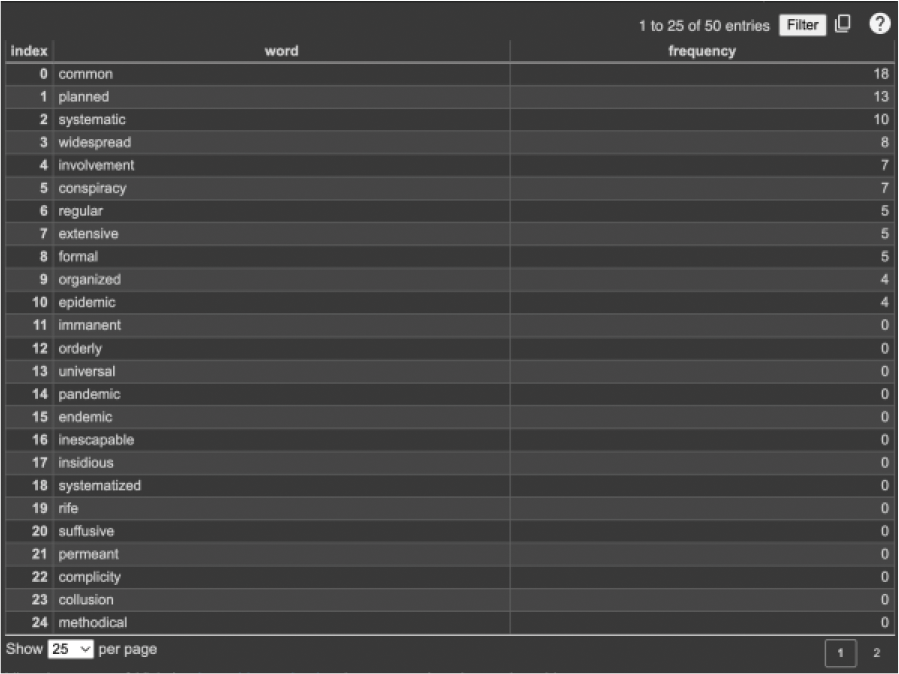
Only 11 of the 50 words appeared in the text (Figure 4). The word that appeared most frequently was “common”, which had 18 appearances. The words “epidemic” and “organized” both appeared four times and were the least common (aside, of course, from the words that did not appear at all).
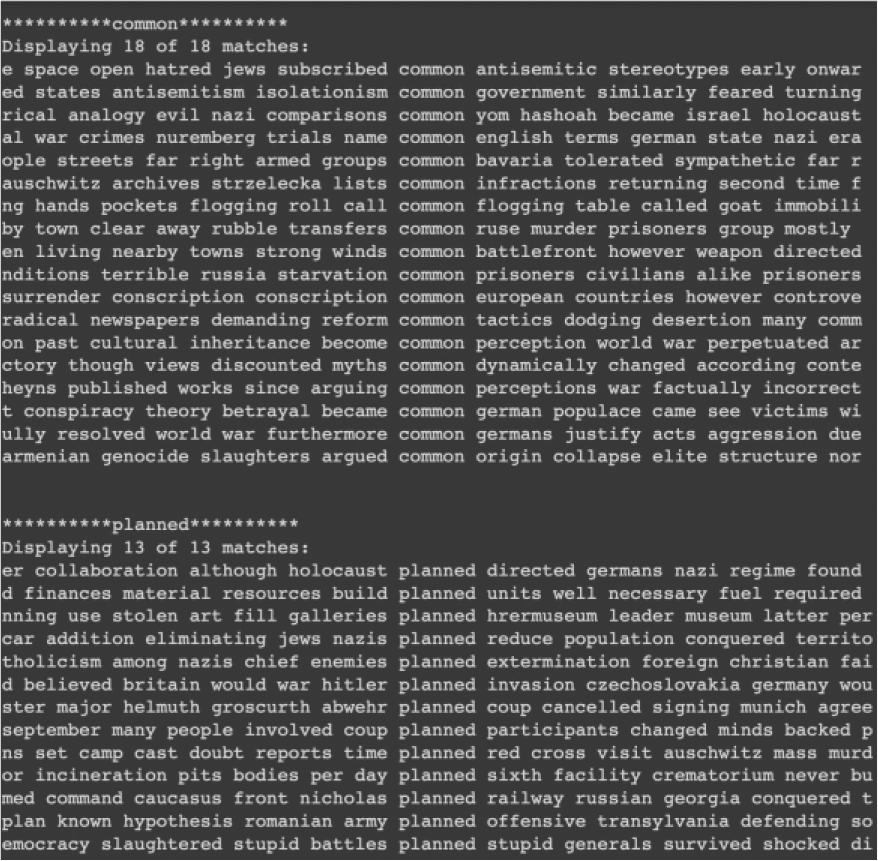
While these frequency data begin to help us understand the content a bit more, they do not necessarily explain the full picture. For this reason, I decided to render the concordance views of the 11 words that did appear in the text. Concordance views are a way of showing every use of a single token within the context surrounding them. Figure 5, for example, shows the concordance view for the word “common”. Here we can see that it is unlikely in most instances that “common” refers to the pervasiveness of Nazism amongst professional, industrial, and civil society. On the other hand, the word “organized” when placed in context may be a more accurate reference to the systematic execution of the Holocaust. In fact, one of the matches displayed has “organized” in the following context: “elites attempt prevent development organized resistance september reinhard.”
3 CONCLUSION
In this project, I performed a variety of data mining techniques on four key Wikipedia articles regarding the Holocaust. This investigation was motivated by my learning more about the systemic nature of the Holocaust while attending a FASPE fellowship program. I asked myself: how much do people know about the culpability of professionals, companies, and other less well-known corporate entities.
The text mining process I applied attempted to gain an understanding of the type of words used in these articles and whether the Wikipedia webpages adequately highlighted the systemic nature of this genocide. In my preliminary findings, it does appear that there exists some language attempting to communicate the structural nature of Nazi crimes during the Third Reich. Although, based on my FASPE fellowship experience where we visited lesser known Holocaust sites such as the Sachsenhausen concentration camp and Brandenburg Euthanasia Centre, were given intimate tours by curatorial staff at museums such as the Topography of Terror, and had the privilege of learning in workshops hosted by cutting-edge Holocaust historians—it is clear to me that the involvement of professionals and corporations in the Holocaust is likely not fully realized by the general public. However, further investigation is warranted to better understand the extent to which online articles communicate the complicity of these groups.
Ian René Solano-Kamaiko was a 2022 FASPE Design and Technology Fellow. He is a Computer Science PhD student at Cornell University.
Notes
- Naomi Baumslag et al. 2005. Murderous medicine: Nazi doctors, human experimentation, and typhus. Praeger Publishers.
- Jesse F Dillard. 2003. Professional services, IBM, and the Holocaust. Journal of Information Systems 17, 2 (2003), 1–16.
- Sarah Federman. 2021. Corporate Leadership and Mass Atrocity. Journal of Business Ethics 172, 3(2021), 407–423.
- Thomas Ferguson and Hans-Joachim Voth. 2008. Betting on Hitler—the value of political connections in Nazi Germany. The Quarterly Journal of Economics 123, 1 (2008), 101–137.
- Hugh I Joffe, Charmaine F Joffe, and Henry Brodaty. 1996. Ageing Jewish Holocaust survivors: anxieties in dealing with health professionals. Medical journal of Australia 165, 9 (1996), 517–520.
- David H Jones. 2000. Moral responsibility in the Holocaust: A study in the ethics of character. Rowman & Littlefield Publishers.
- Geoffrey Jones, Grace Ballor, and Adrian Brown. 2021. Thomas J. Watson, IBM, and Nazi Germany.(2021).
- PD Magnus. 2009. On trusting wikipedia. Episteme 6, 1 (2009), 74–90.
- Lucia Mason, Angela Boldrin, and Nicola Ariasi. 2010. Searching the Web to learn about a controversial topic: are students epistemically active? Instructional Science 38, 6 (2010), 607–633.
- Connor McMahon, Isaac Johnson, and Brent Hecht. 2017. The substantial interdependence of Wikipedia and Google: A case study on the relationship between peer production communities and information technologies. In Eleventh international AAAI conference on web and social media.
- Josiane Mothe and Gilles Sahut. 2018. How trust in Wikipedia evolves: a survey of students aged 11 to 25. Information Research: an international electronic journal 23, 1 (2018), n1.
- Neil Selwyn and Stephen Gorard. 2016. Students’ use of Wikipedia as an academic resource—Patterns of use and perceptions of usefulness. The Internet and Higher Education 28 (2016), 28–34.